hive partitions sample
Personally I have used partitions and bucketing for hive few times.
But since Hive supports these two features I should note them here.
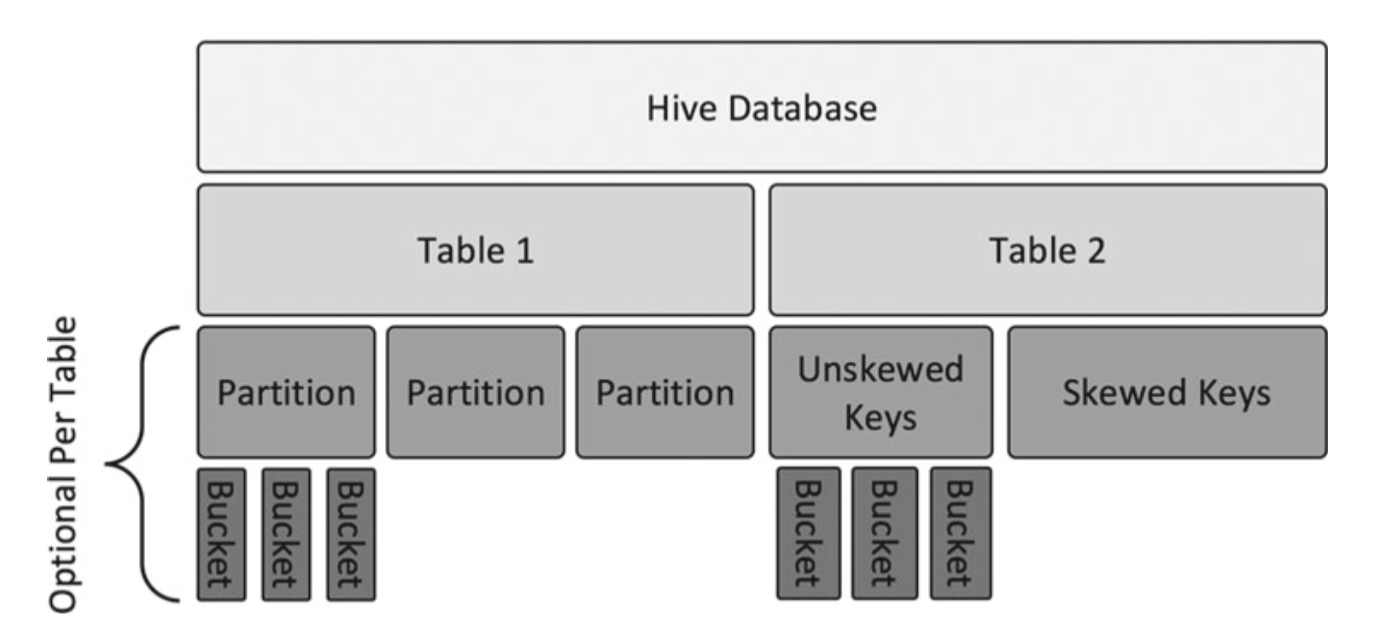
Here is the partitions sample below.
hive> create table transactions_int (
> transdate date,
> transid int,
> custid int,
> fname string,
> lname string,
> item string,
> qty int,
> price float) partitioned by (store string);
OK
hive> INSERT INTO transactions_int PARTITION (store="new york") values ("2016-01-25",101,109,"MATTHEW","SMITH","SHOES",1,112.9);
hive> show partitions transactions_int;
OK
store=new york
Time taken: 0.276 seconds, Fetched: 1 row(s)
hive> select * from transactions_int;
OK
2016-01-25 101 109 MATTHEW SMITH SHOES 1 112.9 new york
Time taken: 0.424 seconds, Fetched: 1 row(s)
When you check files from hdfs command you will see the storage space is separated by partition keys.
$ hdfs dfs -ls /user/hive/warehouse/transactions_int
Found 1 items
drwxr-xr-x - pyh supergroup 0 2022-05-12 10:07 /user/hive/warehouse/transactions_int/store=new york
Partitoning considerations:
- Pick a column for partition key with low to medium Number of Distinct Values (NDVs).
- Avoid partitions that are less than 1 GB (bigger is better).
- Tune Hiveserver2 and Hive Metastore memory for large number of partitions.
- When you use multiple columns for partition key, it will create a nested tree of subdirectories for each combination of partition key columns. You should avoid deep nesting as it can cause too many partitions and hence create very small files.
- When insert data using Hive streaming, if multiple sessions write data to same partitions, it can lead to locking.
- You can modify the schema of a partitioned table; however, once the structure is changed, you cannot modify the data in existing partitions.
- If you are inserting data to multiple partitions in parallel, you should set hive. optimize.sort.dynamic.partition only to True.