dataflow for a classic analysis job
To run a analysis job we first need to collect the data, either via message queue system or via log ingestion.
After getting the original data we have two stacks to analyze them, one is batch based analysis, another is streaming based analysis.
The dataflow looks similar as below.
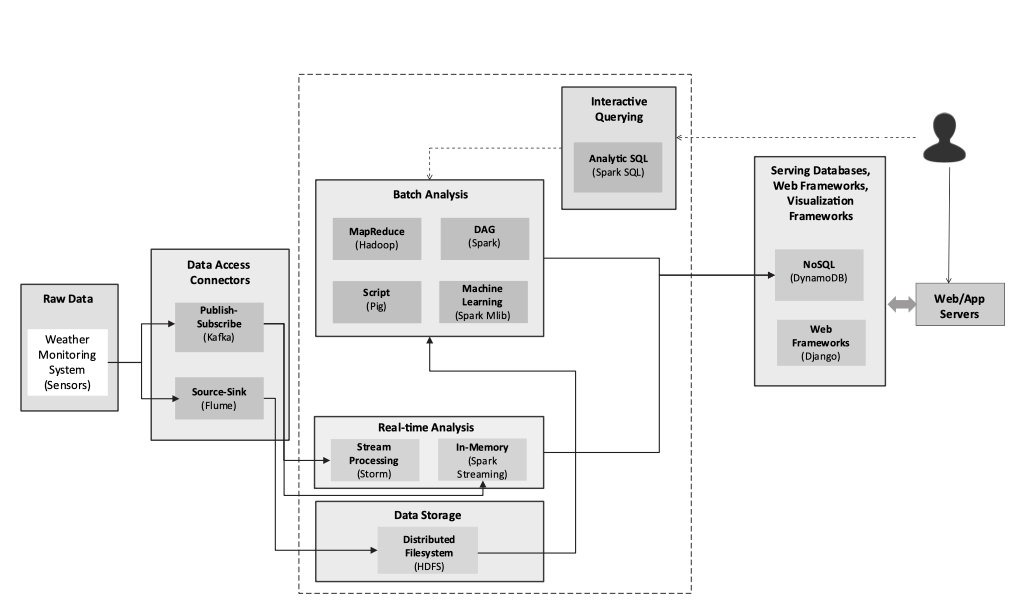
The tech stacks include:
- log ingestion to Hadoop - Apache Flume
- RDBMS to Hadoop - Apache Sqoop
- message queue (mostly working as event streams) - Apache Kafka
- distributed storage - HDFS
- batch computing - Hadoop MR, or Spark RDD
- streaming computing - Apache Storm, Spark streaming
- interactive querying - Spark SQL or Hive